M5Stackとフォント 漢字フォントの表示 UTF8への対応 #m5stack [ESP32]
おおむね成功ですっ!ちぃ、、ですっ!
 さて前回は16×16ドットのフォントでJIS第2水準程度の日本語を表示する。ただし表示できるのはShift-JISコード!と言う内容でしたが、今回はUTF8まで対応してみます。
さて前回は16×16ドットのフォントでJIS第2水準程度の日本語を表示する。ただし表示できるのはShift-JISコード!と言う内容でしたが、今回はUTF8まで対応してみます。
UTF8でJIS第2水準程度をサポートしていれば、日本語の表示ではそれほど苦労しないで済みそうですね。
前回書いた様にここに有るのはShift-JISに対応した漢字のフォントデータ。しかし対応しなければならないのはUTFのコード。
ならばUTFのコードをShift-JISに変換するしかない!
と言う訳で、ここではその手順を書いてみます。ちなみにこれがベストの方法だとは思いませんが、このブログは基本的に備忘録なので。
1.FONTX形式のファイルのShift-JISコードだけの(つまりここではビットマップデータは必要無い)リストを作る。※PCで作業
2.上記リストのコードを16進表記した値(文字列)と、そのコードをバイナリー化した値をレコードとしたファイルを生成する。
以下の様なファイルですね。これはShift-JISのファイルとなります。このファイルをエディタで開くとバイナリー化した値は文字として読めます。※PCで作業
3.このファイルをエディタの機能を使ってUTF8に変換する。以下の様になりますね。見た目はまったく変わりませんが(笑)、漢字はUTF8のコードに直っています。つまり1行毎に16進表記のShift-JISのコードとUTF8のコードの対応が取れました。※PCで作業
4.上記ファイルのUTF8のバイナリーデータを16進表記に変換して、構造体の配列としてCソースファイルを生成します。この時検索性を良くするためにUTF8のバイナリーデータを昇順で配列の並べ替えを行って置きます。
以下の様なファイルを作ります。この場合UTF8のコードは4byte長としています。UTF8のコードは最長で6byteとなるようですが、今回変換した漢字コードは最大でも3byteしか使っていませんでしたので、4byte長で充分だと思います。目的は手持ちのShift-JISコードのフォントデータを利用するだけですから。※PCで作業
5.上記変換データを収めたCソースファイルをプロジェクトに取り込む。
6.文字列を先頭から1byte単位で読み出し、最上位bitが立っていれば漢字、立っていなければASCII文字として処理します。※マイコンで作業
7.漢字であれば上位bitのパターンから後ろに何byte続くか判断し、それらを32bit長の変数に代入し、その値をキーに変換テーブルから該当するShift-JISコードを取得します。※マイコンで作業
8.後は前回の漢字表示処理を行うだけです。※マイコンで作業
プロジェクト一式
※今回の漢字をマイコンで表示させる手順としては、別にM5stackに限らず様々なマイコンで同じ方法が使えると思います。
※しかしフォントデータと変換データを合わせて、かなりの量のROM容量が必要ですね!
参考
ウィキペディア https://ja.wikipedia.org/wiki/UTF-8
今日もスミマセン。
http://d.hatena.ne.jp/snaka72/20100710/SUMMARY_ABOUT_JAPANESE_CHARACTER_CODE
")


 さて前回は16×16ドットのフォントでJIS第2水準程度の日本語を表示する。ただし表示できるのはShift-JISコード!と言う内容でしたが、今回はUTF8まで対応してみます。
さて前回は16×16ドットのフォントでJIS第2水準程度の日本語を表示する。ただし表示できるのはShift-JISコード!と言う内容でしたが、今回はUTF8まで対応してみます。UTF8でJIS第2水準程度をサポートしていれば、日本語の表示ではそれほど苦労しないで済みそうですね。
前回書いた様にここに有るのはShift-JISに対応した漢字のフォントデータ。しかし対応しなければならないのはUTFのコード。
ならばUTFのコードをShift-JISに変換するしかない!
と言う訳で、ここではその手順を書いてみます。ちなみにこれがベストの方法だとは思いませんが、このブログは基本的に備忘録なので。
1.FONTX形式のファイルのShift-JISコードだけの(つまりここではビットマップデータは必要無い)リストを作る。※PCで作業
2.上記リストのコードを16進表記した値(文字列)と、そのコードをバイナリー化した値をレコードとしたファイルを生成する。
以下の様なファイルですね。これはShift-JISのファイルとなります。このファイルをエディタで開くとバイナリー化した値は文字として読めます。※PCで作業
0x889F,亜; // 亜 0x88A0,唖; // 唖 0x88A1,娃; // 娃 0x88A2,阿; // 阿 0x88A3,哀; // 哀
3.このファイルをエディタの機能を使ってUTF8に変換する。以下の様になりますね。見た目はまったく変わりませんが(笑)、漢字はUTF8のコードに直っています。つまり1行毎に16進表記のShift-JISのコードとUTF8のコードの対応が取れました。※PCで作業
0x889F,亜; // 亜 0x88A0,唖; // 唖 0x88A1,娃; // 娃 0x88A2,阿; // 阿 0x88A3,哀; // 哀
4.上記ファイルのUTF8のバイナリーデータを16進表記に変換して、構造体の配列としてCソースファイルを生成します。この時検索性を良くするためにUTF8のバイナリーデータを昇順で配列の並べ替えを行って置きます。
以下の様なファイルを作ります。この場合UTF8のコードは4byte長としています。UTF8のコードは最長で6byteとなるようですが、今回変換した漢字コードは最大でも3byteしか使っていませんでしたので、4byte長で充分だと思います。目的は手持ちのShift-JISコードのフォントデータを利用するだけですから。※PCで作業
const struct SJIS_UTF8_TABLE
{
unsigned short sjis;
unsigned long utf8;
} sjis_utf8_table[] =
{
{0x8198,0x0000C2A7},
{0x814E,0x0000C2A8},
・
・
・
{0xFA55,0x00EFBFA4},
{0x818F,0x00EFBFA5},
};
const int sjis_utf8_table_number = 8127;
5.上記変換データを収めたCソースファイルをプロジェクトに取り込む。
6.文字列を先頭から1byte単位で読み出し、最上位bitが立っていれば漢字、立っていなければASCII文字として処理します。※マイコンで作業
7.漢字であれば上位bitのパターンから後ろに何byte続くか判断し、それらを32bit長の変数に代入し、その値をキーに変換テーブルから該当するShift-JISコードを取得します。※マイコンで作業
8.後は前回の漢字表示処理を行うだけです。※マイコンで作業
プロジェクト一式
※今回の漢字をマイコンで表示させる手順としては、別にM5stackに限らず様々なマイコンで同じ方法が使えると思います。
※しかしフォントデータと変換データを合わせて、かなりの量のROM容量が必要ですね!
参考
ウィキペディア https://ja.wikipedia.org/wiki/UTF-8
今日もスミマセン。
http://d.hatena.ne.jp/snaka72/20100710/SUMMARY_ABOUT_JAPANESE_CHARACTER_CODE
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
M5Stackとフォント 漢字フォントの対応 [ESP32]
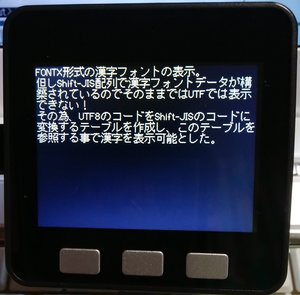
 FONTX形式の漢字フォントの表示。但しShift-JIS配列で漢字フォントデータが構築されているので、UTFでは表示できない!
FONTX形式の漢字フォントの表示。但しShift-JIS配列で漢字フォントデータが構築されているので、UTFでは表示できない!FONTX形式の解説はCHAN氏がされているので、そこを参考にしてね。
http://elm-chan.org/docs/dosv/fontx.html
このブログでも過去記事か有ります。
https://hamayan.blog.so-net.ne.jp/2009-09-19-1
※本当はもっと詳しく書いた記事が有ったのですが、失われた、、、
今回使用しているFONTX形式のフォントデータは力武健次氏が公開されている物を利用させていただきました。もうだいぶ昔の事なので改めて氏のリンク先を探したら、以下のページが有りました。
http://www.k2r.org/gijyutsushi
なぜFONTX形式?
実際のところM5Stackが流行るずいぶん前から組込みで液晶に日本語を表示する事は広く行われてきました。その液晶表示する時に比較的扱い易いフォントデータ形式としてFONTX形式がよく使われています。他にもBDF形式とかですね。
なので、「FONTX形式」で検索してもらえれば、沢山の利用例が見つかります。
なぜShift-JIS?
上記の日本語表示の流行の頃は日本語のコード体系ではShift-JISが一般的だったのです。今でもShift-JIS配列のFree fontを多く見つけられるでしょう。
例えば16×16ドットのフォントで第2水準までサポートした場合のROM容量は250kbyteくらいです。昔のマイコンならいざ知らず、ESP32とかなら組み込んでも余裕ですね!
但し!
現在主流のコードはUTFです。Arduino IDEで日本語を書いた時、そのコードはUTFになっています。UTFのコードをそのままShift-JISのコードに変換できず、これが結構面倒です。組み込みには厳しい状況です。
同じ日本語( 覇漏倭亞琉弩、夜露死苦 )をShift-JISとUTF-8で書いた物をバイナリーエディターで開いた物が以下です。

上がShift-JIS、下がUTF-8N
Shift-JISの文字コードは16bit固定長ですが、UTFでは拡張性?からか8bit~の可変長です。なのでこの場合はデータ量が増えていますね。
さて、UTFのコードからShift-JISのフォントデータにアクセスする方法、どうしましょう?
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
M5Stackとフォント GFXFFへの対応 [ESP32]
 前回ではランレングスに対応しました。今回はGFX Free Fontと言うフォントの対応です。
前回ではランレングスに対応しました。今回はGFX Free Fontと言うフォントの対応です。GFX Free Fontもプロポーショナルフォントですが、特に筆記体を表示するのに向いている様な気がします。
マイコンにとって最も処理の負荷が小さそうなのは等幅フォントですが、等幅フォントでは例えば小文字の'i'が連続した時に、'i'と'i'の間が大きく開いて体裁が良くありません。
プロポーショナルフォントなら文字毎に適切な文字間隔を指定できるので、とても体裁が良くなります。しかし制御が増えるのでその点は良し悪しです。
ランレングスはSPIとは相性が良さそうな気がしますね。
GFXフォントの使い方の解説(本家?)はここから。
https://learn.adafruit.com/adafruit-gfx-graphics-library/using-fonts
Customフォルダーの中のフォントは以下のサイトで生成された物?
http://oleddisplay.squix.ch/#/home
GFX Free Font(GFXFF)を使う為のもっとも簡単な方法は、すでにM5ライブラリに用意されているメソッドを使う事です。
例えば
setFreeFont( GFXFFにアクセスする為の構造体のポインタ );でこれから使用するフォントを選択。
drawString( テキスト, 横位置, 縦位置, フォント番号 );で指定された位置に先に指定されたフォントでテキストを描画します。まあつまりこんな感じで、
M5.Lcd.setFreeFont( &Yellowtail_32 ); // Select the font M5.Lcd.drawString( "hello world.", 0, 0, 1 );
これらメソッドはM5Stack.hには記載されていませんが、M5Display.hの中でTFT_eSPIクラスが継承されているのでIn_eSPI.hを参考にすると良いでしょう。
しかし相変わらずこのメソッドでは画面の右端に行った時に折り返しをしてくれません、、、よね?
折り返しとか改行とかを行いたいなら、自分で描画メソッドを作るしかない?
以下ではその解説を!
1.GFXフォーマットのフォントデータファイルは3つの要素で構成されている。
1) 文字をビットマップデータ化したデータ領域
Yelllowtail_32.hであれば
const uint8_t Yellowtail_32Bitmaps[] PROGMEM
配列名は任意でこのファイルの中でしか利用されないが、static宣言はされていない。
2) 該当文字の属性データ。例えば該当文字のデータが始まる位置を、上記ビットマップデータ
の先頭からのオフセットとか、文字の横サイズ、文字の縦サイズ、次の文字までのピッチ、
描画原点からの横と縦のオフセット等が配列化されている。
3) ビットマップデータ、上記属性データ、行間のピッチをまとめた物。
文字を表示する場合はこの変数をアクセスする事となる。
2.GFXフォーマット
gfxfont.hの中で2つの構造体が定義されている。
1) GFXglyph
typedef struct { // Data stored PER GLYPH
uint16_t bitmapOffset; // Pointer into GFXfont->bitmap
uint8_t width, height; // Bitmap dimensions in pixels
uint8_t xAdvance; // Distance to advance cursor (x axis)
int8_t xOffset, yOffset; // Dist from cursor pos to UL corner
} GFXglyph;
Yelllowtail_32.hの中の文字'A'のGFXglyphレコード
{ 1141, 24, 24, 20, 1, -23 }, // 'A'
bitmapOffset : ビットマップデータ領域の先頭からのオフセット。この場合は1141。
width, height : 文字の横幅 = 24ピクセル。高さ = 24ピクセル。
xAdvance : 次の文字までの横方向のピッチ = 20
xOffset, yOffset : 文字の描画開始位置からの横方向のオフセット = 1。
文字の描画開始位置からの縦方向のオフセット = -23。
2) GFXfont
typedef struct { // Data stored for FONT AS A WHOLE:
uint8_t *bitmap; // Glyph bitmaps, concatenated
GFXglyph *glyph; // Glyph array
uint8_t first, last; // ASCII extents
uint8_t yAdvance; // Newline distance (y axis)
} GFXfont;
Yelllowtail_32.hの中のGFXfontレコード
const GFXfont Yellowtail_32 PROGMEM = {
(uint8_t *)Yellowtail_32Bitmaps,(GFXglyph *)Yellowtail_32Glyphs,0x20, 0x7D, 45};
bitmap : ビットマップデータ全体へのポインタ
glyph : GFXglyph構造体の配列のポインタ
first, last : 最初の文字、最後の文字。ASCIIコードからfirstを引いた値を
GFXglyph構造体配列のインデックスとする。
yAdvance : 次の行までの高さ。
3.GFXフォーマットの文字データの展開
該当文字のGFXglyph構造体レコードを取得すると、該当文字データの開始アドレスを
取得できる。
このデータはランレングス(RUN LENGTH)の様な圧縮は行われておらず、ビット列を
ビットマップとして画面上に展開する。しかしFont16.cの様な無圧縮のビットマップ
データをそのままメモリ領域に展開してしまうと文字サイズが大きい時は必要なメモリ
領域も大きくなってしまうので文字の描画開始位置を指定する事でメモリサイズの
増大を防いでいる。
例えば'A'であれば文字の上の辺りから描画開始しなければならないが、'.'であれば
随分下の位置からの描画開始となる。
以下はYelllowtail_32.hの文字'A'と文字'.'のデータである。
文字'A'のビットマップデータ
0x00,0x00,0x1E,0x00, 0x00,0x3F,0x00,0x00,
0x7E,0x00,0x01,0xEE, 0x00,0x03,0xDC,0x00,
0x07,0x9C,0x00,0x0F, 0x38,0x00,0x1E,0x38,
0x00,0x1C,0x78,0x00, 0x38,0x70,0x00,0x70,
0x70,0x00,0xE0,0xE0, 0x01,0xE0,0xE0,0x03,
0xC1,0xC0,0x7F,0xFF, 0xC0,0x7F,0xFF,0x80,
0x0E,0x03,0x80,0x1C, 0x07,0x00,0x38,0x07,
0x00,0x78,0x0F,0x00, 0x70,0x0E,0x00,0xE0,
0x1E,0x00,0xE0,0x1C, 0x00,0xC0,0x38,0x00, // 'A'
でかい!
文字'.'のビットマップデータ
0x7F,0xE0, // '.'
文字によって横幅、高さ、描画開始位置等の属性が異なり、文字を描画する為には
その情報にアクセスしなければならない。
文字'A'の属性データ
{ 1141, 24, 24, 20, 1, -23 }, // 'A'
文字'.'の属性データ
{ 431, 4, 3, 9, 2, -2 }, // '.'
文字'A'のxOffsetは1、yOffsetは-23。
文字'.'のxOffsetは2、yOffsetは-2。
xOffsetは文字開始位置からの相対位置、yOffsetはyAdvanceからの相対位置となる。
基本的にM5stackの描画は左上から右下方向に開始され、Xが大きくなれば右に、
Yが大きくなれば下に進む。
それぞれの文字の描画開始位置は横方向ならxOffsetから、
縦方向なら yAdvance + yOffset(注1)から開始する。Yelllowtail_32.hのyAdvanceは45である。
お試しプログラムは以下のリンク
https://1drv.ms/u/s!AgxfaDqma1yrhk6AY-NUsBh7pyXb
(注1) とか言いつつソースには高さ方向で調整が入っているじゃあないかい!
※TFT_eSPIクラスにはreadPixelメソッドが存在するので、ピクセルの読み出し可能か?と期待しましたが、見事にFFFFが返ってくるorz
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
M5Stackとフォント ランレングス(RUN LENGTH ENCODING)への対応 [ESP32]
 前回ではランレングスのデコード方法が判らなかったので、非圧縮フォントデータのみ扱いましたが、今回はデコード方法が判ったのでそれに対応しました。
前回ではランレングスのデコード方法が判らなかったので、非圧縮フォントデータのみ扱いましたが、今回はデコード方法が判ったのでそれに対応しました。一応フォントデータのデコード方法ですが、例えばFont32rle.cを見てみると
widtbl_f32[96]と言う配列、chr_f32_20[]と言う配列、chrtbl_f32[96]と言う配列が有る訳ですが、
widtbl_f32はその文字の横幅を示しています。最初の値はASCIIコードでスペースなのですが、そのスペースの横幅はこの場合5ピクセルです。
chr_f32_20は文字のビットパターンで、ここがランレングスで圧縮されています。配列名の最後の2文字はASCIIコード番号を示し、この場合はスペースの20(16進)です。
chrtbl_f32は上記ビットパターンのポインターの配列です。
なので文字の横幅を知りたい時は、ASCIIコード番号からオフセット分を引いた値をwidtbl_f32配列のインデックスにすればアクセスできますし、ビットパターンを知りたい時はASCIIコード番号からオフセット分を引いた値をchrtbl_f32配列のインデックスにすればアクセスできます。
ランレングスのデコードですが、ビットパターンのそれぞれの1byte単位のデータに着目してみます。
例えばASCIIコードでスペースの値は以下です。
PROGMEM const unsigned char chr_f32_20[] =
{
0x7F, 0x1
};
1byteのデータの最上位ビットが色の情報であり、例えば最上位に1が立っていれば1ピクセル表示する。1が立っていなければ1ピクセルの表示は行わないとします。(逆でも構わない)
続く7bitはその色情報が続く長さを示し、0から127までの値を取りえますが、実際はその値に1を加算します。
上記の0x7F, 0x1であれば、127+1+1+1=130ピクセル分表示しない事になります。
さて横幅は5ピクセルですので、130を5で割れば26となり、26は文字高さになります。
実際はこの値はFont32rle.hの中で定義されていますので、この定義を利用する方が良いでしょう。
さて、ランレングスのデコード方法が判ったので、実際にLCDに表示させてみました。
フォントサイズが32まではそれなりにASCIIコードが表示されますが、それ以上のサイズのフォントはまともに表示できるのは数字のみの様です。
ROMサイズをケチったのか?それとも面倒臭かったのか?
ESP32 Arduinoのプロジェクトを置いておきます。
https://1drv.ms/u/s!AgxfaDqma1yrhk6AY-NUsBh7pyXb
※追記
M5Stackの組み込みフォントのヘッダーファイル、例えばFont32rle.hは再帰呼び出しに対応していないので、ファイルの先頭と最後に以下の様な#ifdef文を追加します。Font32rle.hの例。
#ifndef FONT32RLE_h #define FONT32RLE_h #include#define nr_chrs_f32 96 #define chr_hgt_f32 26 #define baseline_f32 19 #define data_size_f32 8 #define firstchr_f32 32 extern const unsigned char widtbl_f32[96]; extern const unsigned char* const chrtbl_f32[96]; #endif /*FONT32RLE_h*/
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
M5Stackとフォント [ESP32]

M5Stackの標準ライブラリでprintメソッドを使った場合、結構文字が小さく表示されます。
しかしライブラリのソース(In_eSPI_Setup.h)を見てみると実際に利用可能なフォントは複数あります。
#define LOAD_GLCD // Font 1. Original Adafruit 8 pixel font needs ~1820 bytes in FLASH #define LOAD_FONT2 // Font 2. Small 16 pixel high font, needs ~3534 bytes in FLASH, 96 characters #define LOAD_FONT4 // Font 4. Medium 26 pixel high font, needs ~5848 bytes in FLASH, 96 characters #define LOAD_FONT6 // Font 6. Large 48 pixel font, needs ~2666 bytes in FLASH, only characters 1234567890:-.apm #define LOAD_FONT7 // Font 7. 7 segment 48 pixel font, needs ~2438 bytes in FLASH, only characters 1234567890:. #define LOAD_FONT8 // Font 8. Large 75 pixel font needs ~3256 bytes in FLASH, only characters 1234567890:-. //#define LOAD_FONT8N // Font 8. Alternative to Font 8 above, slightly narrower, so 3 digits fit a 160 pixel TFT #define LOAD_GFXFF // FreeFonts. Include access to the 48 Adafruit_GFX free fonts FF1 to FF48 and custom fonts
LOAD_GLCDがおそらくprintメソッドで利用されるフォントです。上記の写真の上半分の文字がそれです。小さいですね。
LOAD_FONT2以降をprintメソッドから利用する方法が見つかりません。drawCentreStringやdrawRightStringからは引数に数字でフォントを指定すれば画面上に表示されます。
しかしdrawCentreStringやdrawRightStringはラベル等で利用する事を目的としたのか、改行は利きませんので、長文はうまく行きません。
LOAD_FONT2のフォント(Font16.c)のみ、画面に出力するライブラリを作成してみました。
https://1drv.ms/u/s!AgxfaDqma1yrhk6AY-NUsBh7pyXb
他のフォントはRLE(RUN LENGTH ENCODING)されており、ちょっとデコードの方法が判らなかったので対応していません。
標示した長文が一番上の写真の下側の黄色い文字です。文章が改行されている事が判ります。
これらのフォントはプロポーショナルフォントの様です。比較的見栄えの良い表示が出来ていると思います。
M5Stackのソースには上記プロポーショナルフォント以外に等幅フォントがありました。5×7のフォントで、表示させてみたのが下の写真です。
ところで標準のprintライブラリってこっちが作成したライブラリに比較して文字の表示が圧倒的に速いじゃないですか、あれ、ソースコードを見てみると、直接SPIでLCDにビットデータを転送しているのね!
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
M5StackとMLX90640 [ESP32]
IoTLTで登壇を申し込みました。
https://iotlt.connpass.com/event/124544/?fbclid=IwAR20sd0yigJlk1trNuqP-CdMaMHmnPK10GJ8I9jpyvdpOI_juDaeaEmuHhY
 表示させてみた。MLX90640はマルツで税込で6000円弱で購入可能。実際にはデジキにオーダーされる!
表示させてみた。MLX90640はマルツで税込で6000円弱で購入可能。実際にはデジキにオーダーされる!
MLX90640のメリットは、FLIRと比較して安価で入手が容易な事、測定温度範囲が広い事。
デメリットはFLIRと比較して解像度がだいぶ低い事。
FLIRをデジキで買った時はたいへんだった。まずアメリカの輸出規制に引っ掛かるので、アメリカ政府に軍事目的じゃなく民間利用ですよ~って申請書類を書かねばならない。しかも実際に輸出されるまで長い事、長い事。忘れた頃に発送の通知が来る。たぶん今、アメリカ政府の機関が予算の関係で動いていないので、もっと時間掛かるに違いない!
kicadのプロジェクト(回路図込み)
https://1drv.ms/u/s!AgxfaDqma1yrhkzz561J0Jj7Bng5
と、とりあえずサーモグラフィー表示をするソースコード
https://1drv.ms/u/s!AgxfaDqma1yrhkzz561J0Jj7Bng5
部品表
https://1drv.ms/x/s!AgxfaDqma1yrhk3DE9TKJ_fgpOgd
を公開しました。
省電力でも使える?ように3.3Vと5V電源を操作できるようにしてあります。
MLX90640のライブラリはgitHubで公開しているライブラリを利用しています!(ソースの先頭にライセンスを貼り付け)
基板はPCBGOGOで注文すれば、凄く安く、かつ早く作ってくれます。
基板に注意点があります。
1.うっかりしていましたが、5V電源のFETスイッチのR17は抵抗ではなく青色LEDを実装してください。基板下側がカソードです。
2.LED1、LED2も基板下側がカソードです。
3.MLX90640は円柱形の根本のタブが下側になります。
※こう言うのをWEBブラウザ上で背景の写真とオーバーレイで表示するJava scriptとか知っていたら教えて欲しい。

 二枚目は液晶テレビを撮影。右側に電源が有るのかな?
二枚目は液晶テレビを撮影。右側に電源が有るのかな?

https://iotlt.connpass.com/event/124544/?fbclid=IwAR20sd0yigJlk1trNuqP-CdMaMHmnPK10GJ8I9jpyvdpOI_juDaeaEmuHhY
 表示させてみた。MLX90640はマルツで税込で6000円弱で購入可能。実際にはデジキにオーダーされる!
表示させてみた。MLX90640はマルツで税込で6000円弱で購入可能。実際にはデジキにオーダーされる!MLX90640のメリットは、FLIRと比較して安価で入手が容易な事、測定温度範囲が広い事。
デメリットはFLIRと比較して解像度がだいぶ低い事。
FLIRをデジキで買った時はたいへんだった。まずアメリカの輸出規制に引っ掛かるので、アメリカ政府に軍事目的じゃなく民間利用ですよ~って申請書類を書かねばならない。しかも実際に輸出されるまで長い事、長い事。忘れた頃に発送の通知が来る。たぶん今、アメリカ政府の機関が予算の関係で動いていないので、もっと時間掛かるに違いない!
kicadのプロジェクト(回路図込み)
https://1drv.ms/u/s!AgxfaDqma1yrhkzz561J0Jj7Bng5
と、とりあえずサーモグラフィー表示をするソースコード
https://1drv.ms/u/s!AgxfaDqma1yrhkzz561J0Jj7Bng5
部品表
https://1drv.ms/x/s!AgxfaDqma1yrhk3DE9TKJ_fgpOgd
を公開しました。
省電力でも使える?ように3.3Vと5V電源を操作できるようにしてあります。
MLX90640のライブラリはgitHubで公開しているライブラリを利用しています!(ソースの先頭にライセンスを貼り付け)
基板はPCBGOGOで注文すれば、凄く安く、かつ早く作ってくれます。
基板に注意点があります。
1.うっかりしていましたが、5V電源のFETスイッチのR17は抵抗ではなく青色LEDを実装してください。基板下側がカソードです。
2.LED1、LED2も基板下側がカソードです。
3.MLX90640は円柱形の根本のタブが下側になります。
※こう言うのをWEBブラウザ上で背景の写真とオーバーレイで表示するJava scriptとか知っていたら教えて欲しい。

 二枚目は液晶テレビを撮影。右側に電源が有るのかな?
二枚目は液晶テレビを撮影。右側に電源が有るのかな?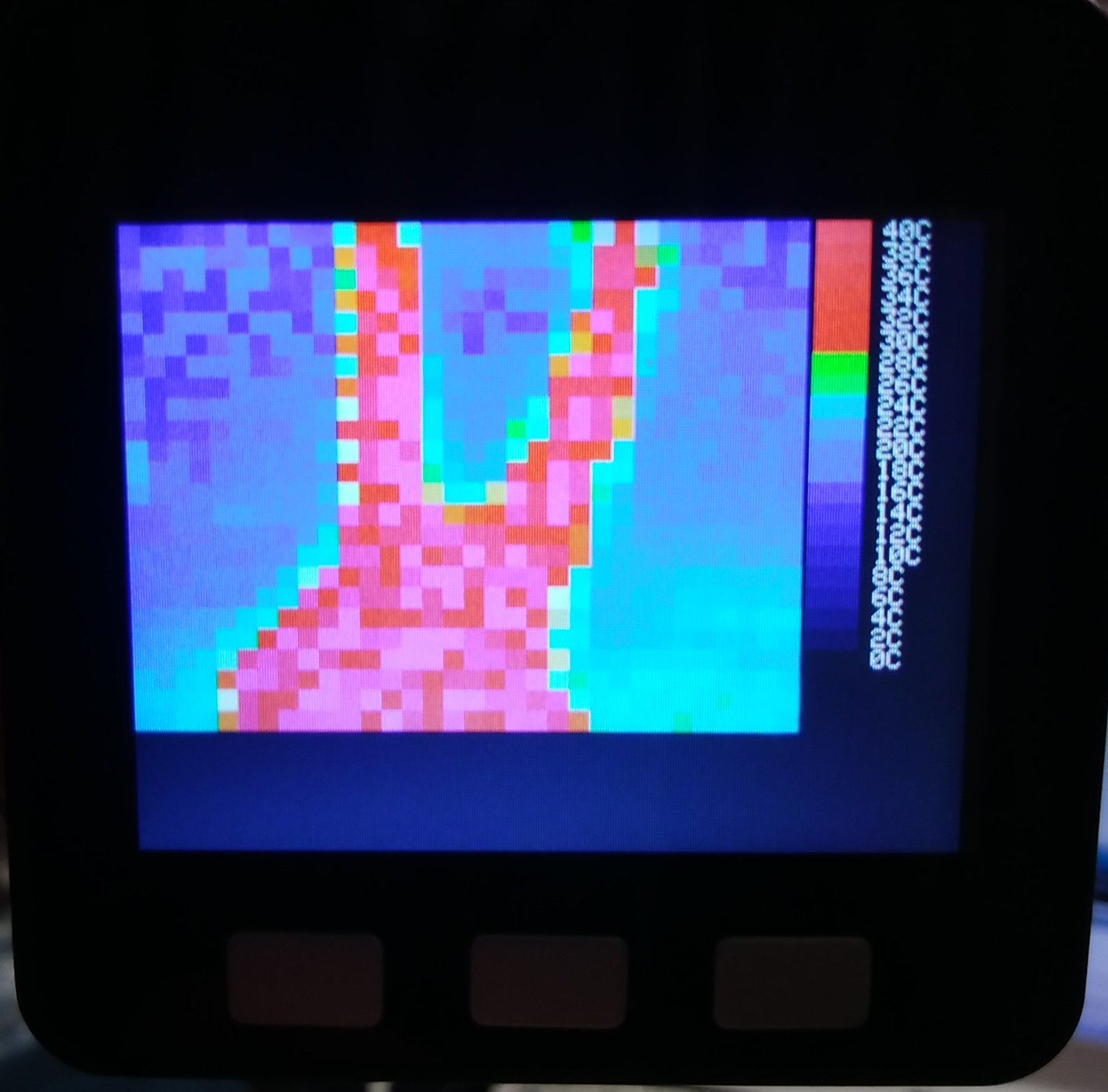
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー

SHOPリンク
μALFAT+H8/Tiny ファイルシステム評価ボード
MSP430-CQ ベースボード
MSP430-CQ ベースボード用デバックアダプター
MSP430F201xベースボード
14pinフラットケーブル
SH2/Tiny(STK-7125)応援企画 28pinソケットヘッダー
パスワールド販売ページ
TACどすえ
お勧め技術書籍
マイコン関係の書籍
Navajo Webカメラ
 |


