M5Stackとフォント 漢字フォントの表示 UTF8への対応 #m5stack [ESP32]
おおむね成功ですっ!ちぃ、、ですっ!
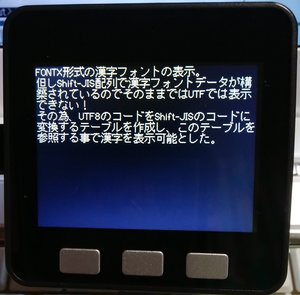 さて前回は16×16ドットのフォントでJIS第2水準程度の日本語を表示する。ただし表示できるのはShift-JISコード!と言う内容でしたが、今回はUTF8まで対応してみます。
さて前回は16×16ドットのフォントでJIS第2水準程度の日本語を表示する。ただし表示できるのはShift-JISコード!と言う内容でしたが、今回はUTF8まで対応してみます。
UTF8でJIS第2水準程度をサポートしていれば、日本語の表示ではそれほど苦労しないで済みそうですね。
前回書いた様にここに有るのはShift-JISに対応した漢字のフォントデータ。しかし対応しなければならないのはUTFのコード。
ならばUTFのコードをShift-JISに変換するしかない!
と言う訳で、ここではその手順を書いてみます。ちなみにこれがベストの方法だとは思いませんが、このブログは基本的に備忘録なので。
1.FONTX形式のファイルのShift-JISコードだけの(つまりここではビットマップデータは必要無い)リストを作る。※PCで作業
2.上記リストのコードを16進表記した値(文字列)と、そのコードをバイナリー化した値をレコードとしたファイルを生成する。
以下の様なファイルですね。これはShift-JISのファイルとなります。このファイルをエディタで開くとバイナリー化した値は文字として読めます。※PCで作業
3.このファイルをエディタの機能を使ってUTF8に変換する。以下の様になりますね。見た目はまったく変わりませんが(笑)、漢字はUTF8のコードに直っています。つまり1行毎に16進表記のShift-JISのコードとUTF8のコードの対応が取れました。※PCで作業
4.上記ファイルのUTF8のバイナリーデータを16進表記に変換して、構造体の配列としてCソースファイルを生成します。この時検索性を良くするためにUTF8のバイナリーデータを昇順で配列の並べ替えを行って置きます。
以下の様なファイルを作ります。この場合UTF8のコードは4byte長としています。UTF8のコードは最長で6byteとなるようですが、今回変換した漢字コードは最大でも3byteしか使っていませんでしたので、4byte長で充分だと思います。目的は手持ちのShift-JISコードのフォントデータを利用するだけですから。※PCで作業
5.上記変換データを収めたCソースファイルをプロジェクトに取り込む。
6.文字列を先頭から1byte単位で読み出し、最上位bitが立っていれば漢字、立っていなければASCII文字として処理します。※マイコンで作業
7.漢字であれば上位bitのパターンから後ろに何byte続くか判断し、それらを32bit長の変数に代入し、その値をキーに変換テーブルから該当するShift-JISコードを取得します。※マイコンで作業
8.後は前回の漢字表示処理を行うだけです。※マイコンで作業
プロジェクト一式
※今回の漢字をマイコンで表示させる手順としては、別にM5stackに限らず様々なマイコンで同じ方法が使えると思います。
※しかしフォントデータと変換データを合わせて、かなりの量のROM容量が必要ですね!
参考
ウィキペディア https://ja.wikipedia.org/wiki/UTF-8
今日もスミマセン。
http://d.hatena.ne.jp/snaka72/20100710/SUMMARY_ABOUT_JAPANESE_CHARACTER_CODE
")


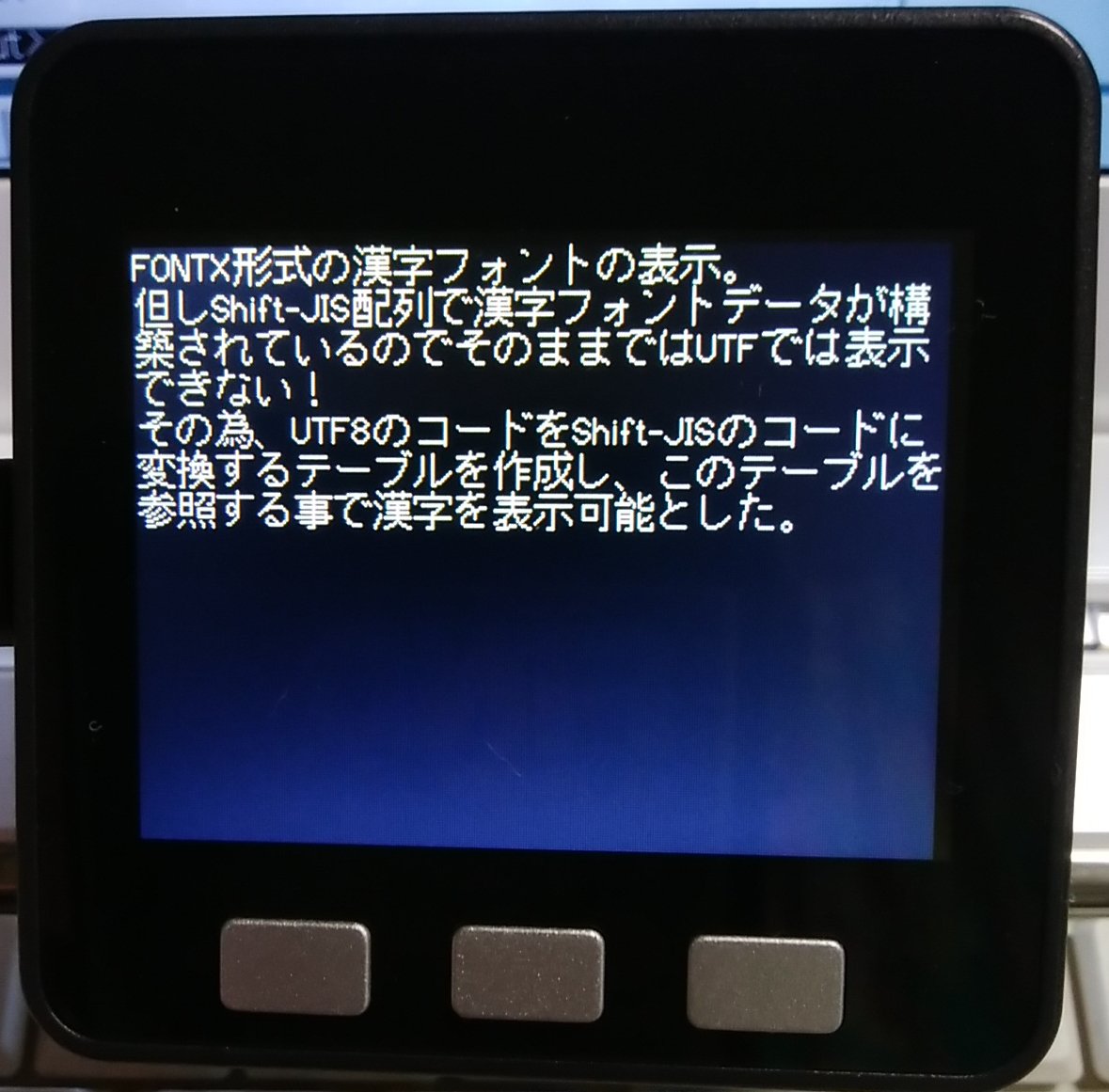 さて前回は16×16ドットのフォントでJIS第2水準程度の日本語を表示する。ただし表示できるのはShift-JISコード!と言う内容でしたが、今回はUTF8まで対応してみます。
さて前回は16×16ドットのフォントでJIS第2水準程度の日本語を表示する。ただし表示できるのはShift-JISコード!と言う内容でしたが、今回はUTF8まで対応してみます。UTF8でJIS第2水準程度をサポートしていれば、日本語の表示ではそれほど苦労しないで済みそうですね。
前回書いた様にここに有るのはShift-JISに対応した漢字のフォントデータ。しかし対応しなければならないのはUTFのコード。
ならばUTFのコードをShift-JISに変換するしかない!
と言う訳で、ここではその手順を書いてみます。ちなみにこれがベストの方法だとは思いませんが、このブログは基本的に備忘録なので。
1.FONTX形式のファイルのShift-JISコードだけの(つまりここではビットマップデータは必要無い)リストを作る。※PCで作業
2.上記リストのコードを16進表記した値(文字列)と、そのコードをバイナリー化した値をレコードとしたファイルを生成する。
以下の様なファイルですね。これはShift-JISのファイルとなります。このファイルをエディタで開くとバイナリー化した値は文字として読めます。※PCで作業
0x889F,亜; // 亜 0x88A0,唖; // 唖 0x88A1,娃; // 娃 0x88A2,阿; // 阿 0x88A3,哀; // 哀
3.このファイルをエディタの機能を使ってUTF8に変換する。以下の様になりますね。見た目はまったく変わりませんが(笑)、漢字はUTF8のコードに直っています。つまり1行毎に16進表記のShift-JISのコードとUTF8のコードの対応が取れました。※PCで作業
0x889F,亜; // 亜 0x88A0,唖; // 唖 0x88A1,娃; // 娃 0x88A2,阿; // 阿 0x88A3,哀; // 哀
4.上記ファイルのUTF8のバイナリーデータを16進表記に変換して、構造体の配列としてCソースファイルを生成します。この時検索性を良くするためにUTF8のバイナリーデータを昇順で配列の並べ替えを行って置きます。
以下の様なファイルを作ります。この場合UTF8のコードは4byte長としています。UTF8のコードは最長で6byteとなるようですが、今回変換した漢字コードは最大でも3byteしか使っていませんでしたので、4byte長で充分だと思います。目的は手持ちのShift-JISコードのフォントデータを利用するだけですから。※PCで作業
const struct SJIS_UTF8_TABLE
{
unsigned short sjis;
unsigned long utf8;
} sjis_utf8_table[] =
{
{0x8198,0x0000C2A7},
{0x814E,0x0000C2A8},
・
・
・
{0xFA55,0x00EFBFA4},
{0x818F,0x00EFBFA5},
};
const int sjis_utf8_table_number = 8127;
5.上記変換データを収めたCソースファイルをプロジェクトに取り込む。
6.文字列を先頭から1byte単位で読み出し、最上位bitが立っていれば漢字、立っていなければASCII文字として処理します。※マイコンで作業
7.漢字であれば上位bitのパターンから後ろに何byte続くか判断し、それらを32bit長の変数に代入し、その値をキーに変換テーブルから該当するShift-JISコードを取得します。※マイコンで作業
8.後は前回の漢字表示処理を行うだけです。※マイコンで作業
プロジェクト一式
※今回の漢字をマイコンで表示させる手順としては、別にM5stackに限らず様々なマイコンで同じ方法が使えると思います。
※しかしフォントデータと変換データを合わせて、かなりの量のROM容量が必要ですね!
参考
ウィキペディア https://ja.wikipedia.org/wiki/UTF-8
今日もスミマセン。
http://d.hatena.ne.jp/snaka72/20100710/SUMMARY_ABOUT_JAPANESE_CHARACTER_CODE
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
- 出版社/メーカー: スイッチサイエンス
- メディア: おもちゃ&ホビー
2019-03-23 10:49
nice!(0)
コメント(0)

SHOPリンク
μALFAT+H8/Tiny ファイルシステム評価ボード
MSP430-CQ ベースボード
MSP430-CQ ベースボード用デバックアダプター
MSP430F201xベースボード
14pinフラットケーブル
SH2/Tiny(STK-7125)応援企画 28pinソケットヘッダー
パスワールド販売ページ
TACどすえ
お勧め技術書籍
マイコン関係の書籍
Navajo Webカメラ
 |



コメント 0