STM32F103のDMAの転送タイミングを見てみよう [ARM&Cortex-M3]
WEのパルスを見てみました。つまり書き込みサイクルです。
さて転送元にRAM領域、アドレスをインクリメントした場合が掲載されていませんですが、結果から言えばRAM領域でアドレス固定と変わりませんでした。
昨日のフレームレートの話に戻りますが、転送元をRAM領域とした場合のフレームレートは45fpsでした。
計測した書き込みサイクルは168nsなので、これを画面いっぱい分の転送を行うと168ns×480×272時間掛かる事になりますから約45.6fpsですね。
また、転送元をROM領域、アドレスインクリメント有りの場合の書き込みサイクルは210nsなので、
210ns×480×272で約36.5fpsとなります。
おお!大体計算と実測は合っていますね。
ROM領域とRAM領域の転送速度の違いの一つの理由としてアクセス速度の違いが考えられます。
STM32F103の内蔵RAMはno waitでアクセス可能であった筈ですが、ROM領域はRAMより遅く、72MHzで走る場合は2wait挿入されます。
インストラクションコードの場合は一旦バッファされてパイプラインの流れを乱さない様にはなっているみたいですが、データの場合はもろに2waitが効いてしまうのかもしれませんね。
この辺の詳しいところはAMBAと言うのでしたっけ、ARMのバスアーキテクチャを勉強しないと判らないです。
しかしシンクロの波形を見る限り、結構上手く捌けていますよね。
Cortex M3のCPUバス周りのブロック図を見ると結構複雑に思えますが、その分このアービター周りはよく考えられているのだろうと思います。
以下はFSMCの設定例。バンク1にグラフィックLCD ICをSRAM相当で接続。バスは16bitサイズ。
waitは少し多めに入っています。
余談
STM32F103のマニュアルのFSMCの章はやけに長くて読むのは本当に大変、日本語の解説も無いですしね。
と、読むのは大変な割に、設定はそれ程でもない。あ!、でもこれDRAMはサポートされていませんね。
")
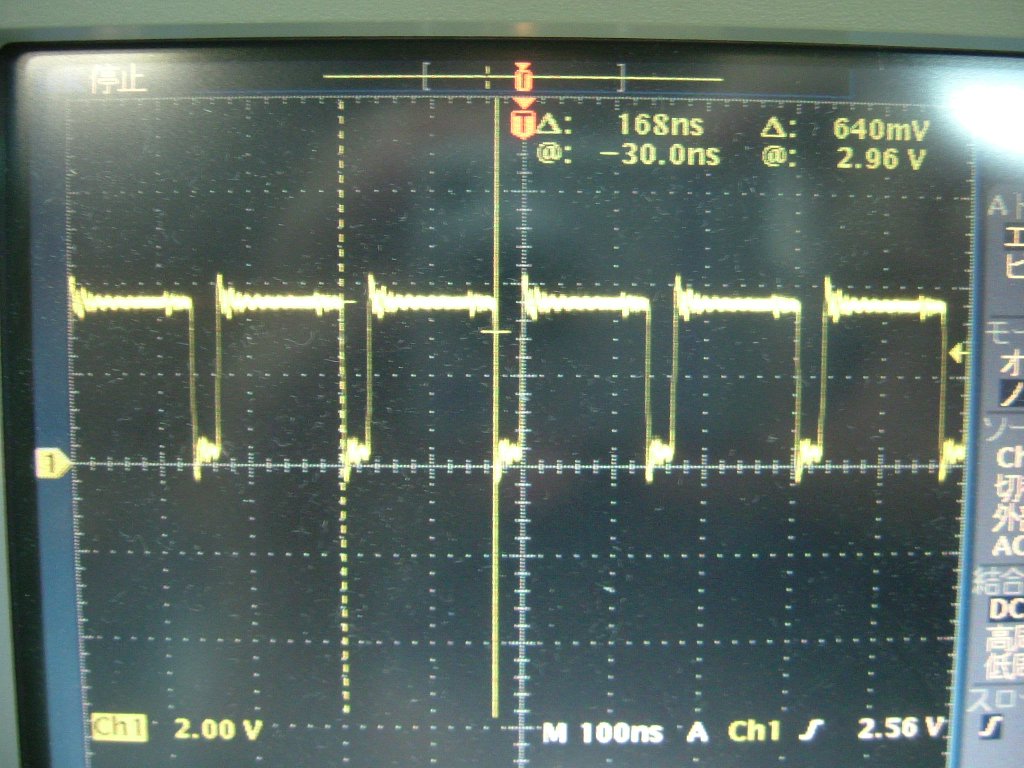
| 変数(RAM上のデータ)をDMAで転送。RAMのアドレスは固定されています。 書き込みサイクルは168nsである事が判ります。波形は比較的綺麗なので、外乱があまり無い事が想定されます。 |
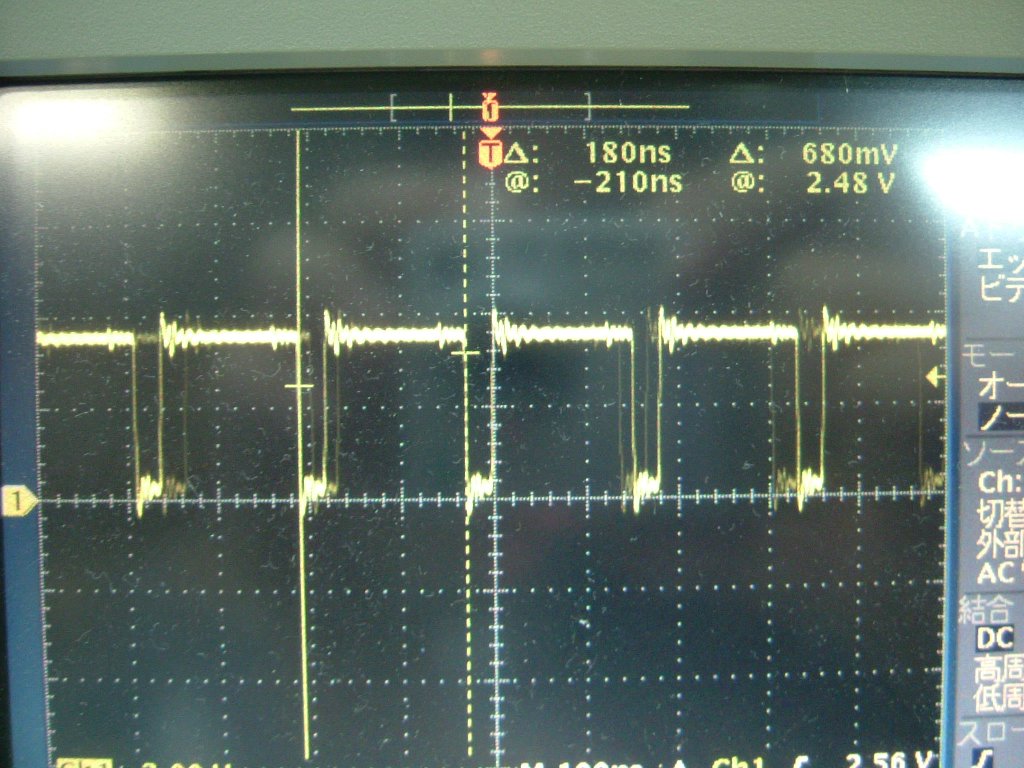
| ROM領域の先頭をDMAで転送。アドレスは固定されています。 書き込みサイクルは180nsである事が判ります。先のRAM固定アドレスに比較すれば周期に若干乱れが見れるので、なんらかの外乱があると思われます。 |
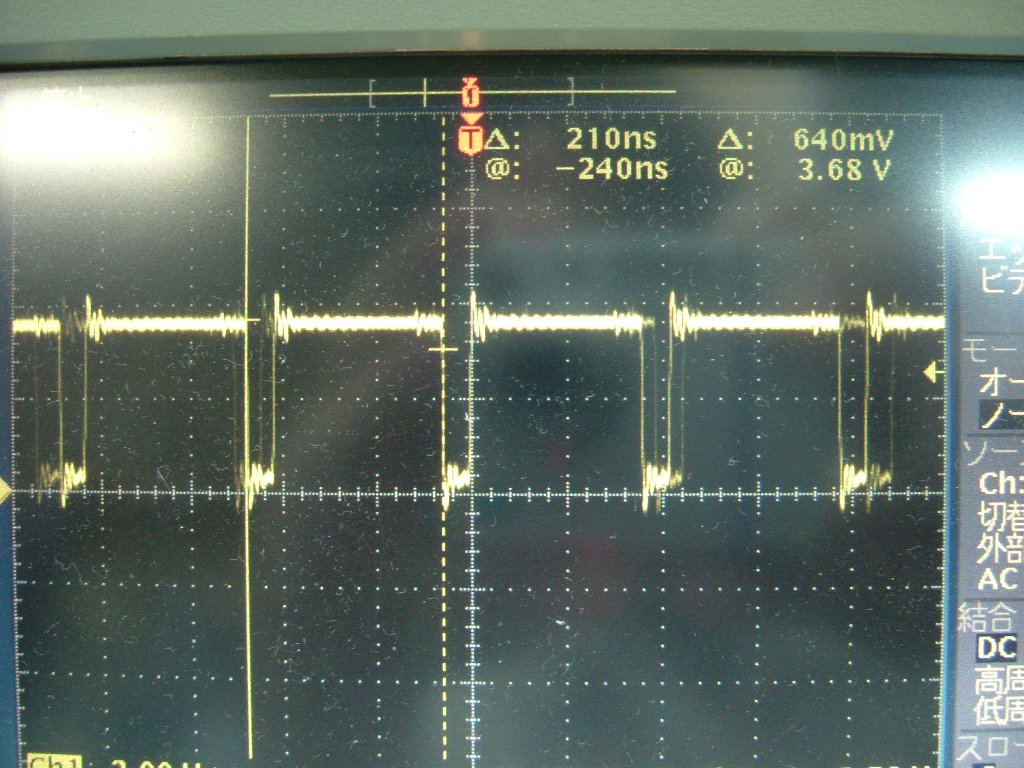
| ROM領域のデータを転送、転送元のROMのアドレスはインクリメントさせています。 転送元は上の場合と同じROM領域なのに、書き込みサイクル時間が延びているのが判ります。アドレスをインクリメントさせると時間が延びる要素が有るのでしょうか?。 サイクル時間は210nsでした。 |
さて転送元にRAM領域、アドレスをインクリメントした場合が掲載されていませんですが、結果から言えばRAM領域でアドレス固定と変わりませんでした。
昨日のフレームレートの話に戻りますが、転送元をRAM領域とした場合のフレームレートは45fpsでした。
計測した書き込みサイクルは168nsなので、これを画面いっぱい分の転送を行うと168ns×480×272時間掛かる事になりますから約45.6fpsですね。
また、転送元をROM領域、アドレスインクリメント有りの場合の書き込みサイクルは210nsなので、
210ns×480×272で約36.5fpsとなります。
おお!大体計算と実測は合っていますね。
ROM領域とRAM領域の転送速度の違いの一つの理由としてアクセス速度の違いが考えられます。
STM32F103の内蔵RAMはno waitでアクセス可能であった筈ですが、ROM領域はRAMより遅く、72MHzで走る場合は2wait挿入されます。
インストラクションコードの場合は一旦バッファされてパイプラインの流れを乱さない様にはなっているみたいですが、データの場合はもろに2waitが効いてしまうのかもしれませんね。
この辺の詳しいところはAMBAと言うのでしたっけ、ARMのバスアーキテクチャを勉強しないと判らないです。
しかしシンクロの波形を見る限り、結構上手く捌けていますよね。
Cortex M3のCPUバス周りのブロック図を見ると結構複雑に思えますが、その分このアービター周りはよく考えられているのだろうと思います。
以下はFSMCの設定例。バンク1にグラフィックLCD ICをSRAM相当で接続。バスは16bitサイズ。
waitは少し多めに入っています。
/*************************************************************************/
/* プロセッサ外部バスを有効にする */
/*************************************************************************/
static void ExtBusInit( void )
{
FSMC_BCRx *bcr1 = (FSMC_BCRx *)(FSMC_Bank1 + 0);
FSMC_TCRx *tcr1 = (FSMC_TCRx *)((char *)FSMC_Bank1 + 4);
FSMC_BWTRx *bwtr1 = (FSMC_BWTRx *)(FSMC_Bank1E + 0);
bcr1->BIT.ASYNCWAIT = 0; /*外部waitは使用しない*/
bcr1->BIT.EXTMOD = 1; /**/
bcr1->BIT.MWID = 1; /*16bit bus*/
bcr1->BIT.MTYP = 0; /*sram select*/
bcr1->BIT.MUXEN = 0; /*non multiplexed bus*/
bcr1->BIT.MBKEN = 1; /**/
/*読み込み側設定*/
tcr1->BIT.ACCMOD = 0; /*access mode a*/
tcr1->BIT.DATAST = 9; /**/
tcr1->BIT.ADDSET = 1; /**/
/*書き込み側設定*/
bwtr1->BIT.ACCMOD = 0; /**/
bwtr1->BIT.DATAST = 2; /**/
bwtr1->BIT.ADDSET = 1; /**/
}
余談
STM32F103のマニュアルのFSMCの章はやけに長くて読むのは本当に大変、日本語の解説も無いですしね。
と、読むのは大変な割に、設定はそれ程でもない。あ!、でもこれDRAMはサポートされていませんね。
ARM Cortex‐M3システム開発ガイド―最新アーキテクチャの理解からソフトウェア開発までを詳解 (Design Wave Advance)
- 作者: Joseph Yiu
- 出版社/メーカー: CQ出版
- 発売日: 2009/05
- メディア: 単行本
2009-09-29 20:07
nice!(0)
コメント(5)
トラックバック(0)

SHOPリンク
μALFAT+H8/Tiny ファイルシステム評価ボード
MSP430-CQ ベースボード
MSP430-CQ ベースボード用デバックアダプター
MSP430F201xベースボード
14pinフラットケーブル
SH2/Tiny(STK-7125)応援企画 28pinソケットヘッダー
パスワールド販売ページ
TACどすえ
お勧め技術書籍
マイコン関係の書籍
Navajo Webカメラ
 |



RAMのデータバス幅とROMのデータバス幅が異なっていて、アクセス時間が異なるとか、非アラインアクセスには、ペナルティがあるとか、っていう可能性はありませんか。
某16ビットマイコンでは、16ビット幅のデータバスを使っているのだけど、過去の製品との互換性のため、非アラインでのアクセスが避けられません。しかたがないので、RAMだけには、非アラインアクセスも許すメカニズムが入っていたりします。確か特許として成立したはずです。私のじゃないけど。
> でもこれDRAMはサポートされていませんね。
DRAMのリフレッシュのために、DMAを使うなんてバチあたりな事は出来ないという事ですか?
by noritan (2009-09-29 21:23)
> 非アラインアクセスには、ペナルティがあるとか、っていう可能性はありませんか。
勿論非アラインアクセスを行えば2回に別けて転送が行われるので、その分は遅くなりそうです。
しかし、今回の実験では32bit境界上のデータを16bit単位で転送しているので、必ずアラインアクセスになっています。
> DRAMのリフレッシュのために、DMAを使うなんてバチあたりな事は出来ないという事ですか?
いやいやそんな話ではないのですが、PSRAMは接続できるみたいです。
しかしPSRAMって使った事ないなぁ。アクセス速度は遅いみたいだけれど、シーケンシャルなら早いのかな?。
by hamayan (2009-09-29 22:59)
> 32bit境界上のデータを16bit単位で転送している
すると、ROMに一種のキャッシュが内蔵されていて、16ビット転送二回分を32ビット転送の時間で処理している可能性もありますね。
もしかしたら、1ROW分のキャッシュがあって、16回に1回だけWAITが入っているのかもしれない。
# 予測先読みをしていて、外れた時にペナルティがある、なんて高度な機能でもあるのかな?
by noritan (2009-09-30 10:51)
ところで、PSRAMって、何の略でしょうか。 RM0008の中を探したのだけど、"Cellular RAM"という余計に謎の言葉しか見つからなかった。
# Pseudo SRAM (擬似SRAM)も略したらPSRAMだけど、これなのかな?
by noritan (2009-10-01 20:36)
CRAM(Cellular RAM)なんて言葉はこのマニュアルで初めて見ましたよ(笑)。
PSRAMは勿論擬似SRAMです。
ただのSRAMに比べて安いし、容量も大きいけれど、このマイコンに20何本もアドレス線、16本もデータ線を繋ぐのは嫌になっちゃうな。
ピンアサインを見ると唖然としてしまいます。
普通のDRAMならアドレス線だけでも半分近くに減らせるのに。
by hamayan (2009-10-01 20:53)