STM32F103のDMAの転送タイミングを見てみよう 2 [ARM&Cortex-M3]
DMA転送中はCPUをSLEEPに入れて置いたらどうなるんでしょう?と言う旨のコメントをいただいたので、やってみました。
SLEEPに入れるにはWFIコマンドを実行します。
C言語で実現するにはcortexm3_macro.hの中のvoid __WFI(void);を実行するだけです。
DMA転送が完了するまでWFIでSLEEPに入るようにしている為に、ほとんどの時間はCPUは停止しています。但しシステムタイマー等の幾つかの割り込みは発生する為、完全停止と言う訳ではありません。
WFIで停止したCPUは割り込みで起床されます。
ROM領域からの転送の場合、CPUが停止していなければバスの使用はCPUと仲良く利用する事となりますが、CPUが停止していればDMA側がバスを使い放題となるんでしょう。その為アドレス固定の場合はRAMからの転送並になりました。
しかし依然としてアドレスインクリメントの場合はサイクルが長くなっていますが、これの理由は今一つ判りません。
聞けるチャンスが有ったら、今度聞いてみるかな!。
そう言えば今までのマイコンの場合、DMAにはバーストモードやサイクルスチールモードとかが有って、そのどちらかを選択して来たのですが、このCortex M3のDMAにはその選択が無いのですね。
これはバスの帯域をDMAが独占するのではなく、少なくともCPU側に半分の帯域を保証しているから上記の選択肢が無いのかもしれません。
関係無いけれどこの本、結構出ていますね。
")
SLEEPに入れるにはWFIコマンドを実行します。
C言語で実現するにはcortexm3_macro.hの中のvoid __WFI(void);を実行するだけです。
|
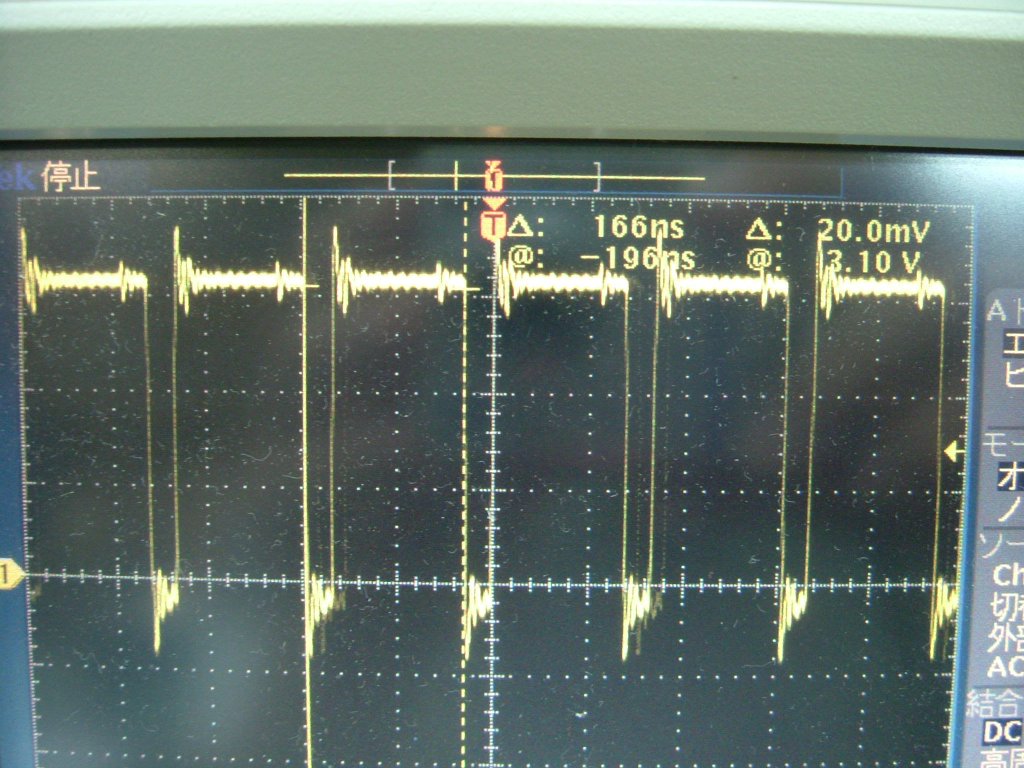
転送元をROM領域の先頭とし、転送元、転送先アドレスを固定した場合です。お!、RAM並に書き込みサイクル時間が短くなっているのが判ります。 |
|
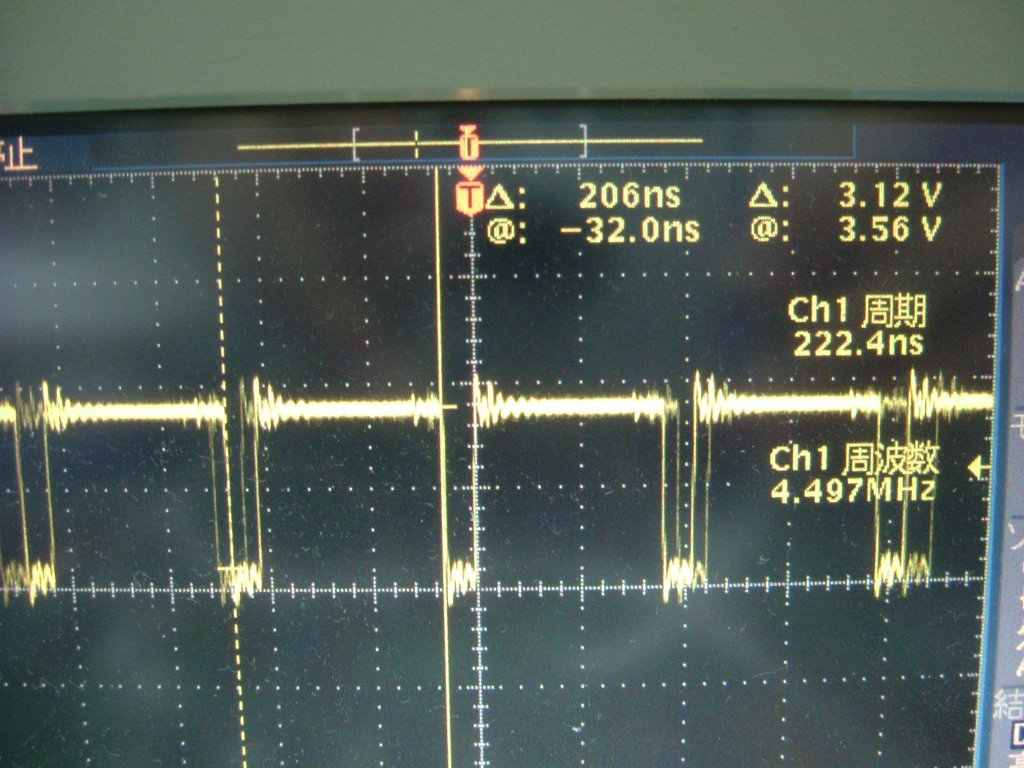
今度は転送元アドレスをインクリメントしています。こちらは従来とあまり変わり有りません。 |
DMA転送が完了するまでWFIでSLEEPに入るようにしている為に、ほとんどの時間はCPUは停止しています。但しシステムタイマー等の幾つかの割り込みは発生する為、完全停止と言う訳ではありません。
WFIで停止したCPUは割り込みで起床されます。
ROM領域からの転送の場合、CPUが停止していなければバスの使用はCPUと仲良く利用する事となりますが、CPUが停止していればDMA側がバスを使い放題となるんでしょう。その為アドレス固定の場合はRAMからの転送並になりました。
しかし依然としてアドレスインクリメントの場合はサイクルが長くなっていますが、これの理由は今一つ判りません。
聞けるチャンスが有ったら、今度聞いてみるかな!。
そう言えば今までのマイコンの場合、DMAにはバーストモードやサイクルスチールモードとかが有って、そのどちらかを選択して来たのですが、このCortex M3のDMAにはその選択が無いのですね。
これはバスの帯域をDMAが独占するのではなく、少なくともCPU側に半分の帯域を保証しているから上記の選択肢が無いのかもしれません。
関係無いけれどこの本、結構出ていますね。
- 作者: 鄭 立
- 出版社/メーカー: リックテレコム
- 発売日: 2006/02
- メディア: 単行本
2009-09-30 21:08
nice!(0)
コメント(13)
トラックバック(0)

SHOPリンク
μALFAT+H8/Tiny ファイルシステム評価ボード
MSP430-CQ ベースボード
MSP430-CQ ベースボード用デバックアダプター
MSP430F201xベースボード
14pinフラットケーブル
SH2/Tiny(STK-7125)応援企画 28pinソケットヘッダー
パスワールド販売ページ
TACどすえ
お勧め技術書籍
マイコン関係の書籍
Navajo Webカメラ
 |



わざわざ検証までしてもらってありがとうございます。
この結果からすると、ibusとdbusが衝突したからといって性能に影響は少なそうですね。
アドレス更新すると遅い理由がわかりませんが、まさかDMAのアドレス更新に1クロック使ってるとか?w
ちなみにZigBee開発ハンドブックは会社に3冊あります。
実験結果から推察した内容が信じれられなかったらしく部長と課長が注文していて、自分で頼んでいた(自分でも信用してなかったw)のを含めて同じ日に3冊届きました。
ARMは昔買ったアーキテクチャの本だけなので、Cortex-M3の本を購入予定です。
by おる (2009-10-01 00:19)
DMA中に条件によってCPUがどの程度動くのか素朴な疑問があり、実験結果は興味深いです。
例えば、DMA転送しながらレジスタのインクリメントを平行して行えるかなど自分も実験したいと思っています。STM32(Cortex-M3)のアーキでは、ROMからDMA転送した場合、命令フェッチとDMAがIbus上で競合するため、hamayanさんの検証結果からDMA転送とレジスタincは交互に動く。SRAMからのDMAだと、SRAMアクセスはDbus経由のためレジスタincの命令フェッチと競合せず、ひょっとして並列動作できるとか。。
by todotani (2009-10-01 07:29)
> ARMは昔買ったアーキテクチャの本だけなので、Cortex-M3の本を購入予定です。
是非!。私はこれが始めてのARMなので、実際右も左も判らない状態です。
色々教えていただけたら幸いです。
by hamayan (2009-10-01 08:59)
> DMA転送とレジスタincは交互に動く。
「DMA転送と命令フェッチは交互に動く」ですね。
DMAとCPUで競合が起きた場合はラウンドロビンで解決するので、CPU側は帯域の半分は確保されています。
また一回のフェッチで64bit読み出す様な事を何処かで読んだ気がするのですが、その点でもボトルネックは小さくなっていると思います。
by hamayan (2009-10-01 09:30)
> DMA転送と命令フェッチは交互に動く
これは、APPLE][で使われていたサイクルスチールと同じ考え方ですね。
APPLE][に使われていた6502の場合には、Eクロックに同期して全てのシステムが動作します。これをEクロックがHIGHの時にはCPUが、LOWの時にはビデオRAMがバスを占有する仕組みにしました。結果として、クロック周波数を上げることが出来なかったのですが、当時の16KbDRAMは、CPUよりも高速だったので、750kHzという高速動作が可能になったと記憶しています。
う~ん、古い話ばかり、思い出してしまう。
by noritan (2009-10-01 10:44)
http://www.st.com/stonline/products/literature/pm/13259.pdf
上の 2.2.2 D-Code interface で
This interface uses the Access Time Tuner block of the prefetch buffer.
直訳して先読みバッファを使用していると仮定すると、
同一アドレスからの読み出しはROMのアクセスタイムに影響しないため(常にヒット)でRAMと同等になり、連続アクセスの場合はミスヒットした場合にアービタで1、ROMで2クロック追加されて3クロック分遅くなる。速度のばらつきは、ヒットした場合とミスヒットの時間差と考えると合うのかな?そうすると8バイトおきに210nsになっているのかどうかでわかるかもしれませんね。
先読みバッファは、ibusでも使用している(こっちが優先)のでCPUを止めてるとdbusで有効利用できるとか。
by おる (2009-10-01 13:43)
おるさんにご紹介いただいたマニュアルを読み始めました。全然、図が出てこないんですけど。
フラッシュメモリは、命令としてもデータ(literal pool)としても使用することができ、同じメモリ空間にマッピングされます。命令フェッチはI-Codeバスをデータ読み出しにはD-Codeバスが使われます。
I-Codeバスには8バイトのプリフェッチバッファが二組接続されていて、CPUは、それぞれのバッファから直接命令を読み出します。(direct-mapped)プリフェッチバッファが二組あるということで、片方のバッファの命令を実行している裏でもう一方のプリフェッチバッファに命令を充填することが出来ます。こうすることで、CPUから見たときのフラッシュメモリからの命令読み出し時間がキャンセルできることになります。このプリフェッチバッファが8バイトであることから、分岐先アドレスを64ビット境界に配置すると効果的だそうです。
じゃあ、I-CodeバスとD-Codeバスの両方から読み出し要求が来たらどうするかというと、D-Codeバスの方が優先されます。
肝心のD-Codeバスのところは、今から読みます。
by noritan (2009-10-01 15:36)
http://www.st.com/stonline/products/literature/rm/13902.pdf
リファレンス・マニュアルRM0008にたどりつきました。
> バーストモード
DMAコントローラの章を読んでいくと、p182に"memory-to-memory mode"という言葉が出てきます。メモリ間転送専用モードのようですが、これが一般にバーストモードと呼ばれているものと同等なのではないでしょうか。
使い方は、CCRxレジスタのMEM2MEMビット(bit14)をセットしてENビット(bit0)もセットすると、たちどころに転送が行われ、カウンタがゼロになるまでDMAが続くそうです。
by noritan (2009-10-01 16:41)
> メモリ間転送専用モードのようですが、これが一般にバーストモードと呼ばれているものと同等なのではないでしょうか。
某マニュアルの内容の要約
「バーストモードでは、DMACは一旦バス権を得ると、転送終了条件が満たされるまでバス権を開放せずに転送を継続します。」
by hamayan (2009-10-01 17:19)
見つけた。RM0008の48ページです。
> Using DMA: DMA accesses Flash memory on the DCode bus
> and has priority over ICode instructions.
> The DMA provides one free cycle after each transfer.
> Some instructions can be performed together
> with DMA transfer.
DMAを使うとき、DMAがDCodeバスを通じてFlashメモリをアクセスするときは、ICodeバスからの命令読み込みよりも優先されます。
DMAは1転送あたり1空きサイクルを消費します。
いくつかの命令は、DMA転送と同時に実行されます。
二つ目がwait以外にROMアクセスが遅い要因になっていると思われます。また、三つ目に書いてあるように、CPUが動作中でもDCodeバス権を必要としない命令であれば、DMA読み出しが並行して実行されるようです。これが、アドレスをインクリメントした際の乱れとなって見えるのではないでしょうか。
この複雑な条件でサイクル数を割り出すんですか?
「出たとこ勝負」にしたくなっちゃうな。
by noritan (2009-10-01 20:21)
> この複雑な条件でサイクル数を割り出すんですか?
> 「出たとこ勝負」にしたくなっちゃうな。
笑!
まあ普通はCPUがどれだけバスの利用時間を確保できるかを検討するので、そこはワーストケースが判っているので良いのではないかと。
CPUとDMAがバスの競合を起こしても、今までに比べたらこれだけペナルティを減らしましたよ!ってところが、とてもモダンなアーキテクチャのマイコンだなぁ!と思ってしまうところで。
DMAはCortex M3の売りの一つみたいですし。
by hamayan (2009-10-01 21:00)
ハーバードアーキテクチャでパイプラインもってて、命令のプリフェッチまでしてるとサイクル数の計算はまずできませんね。
処理時間を求めるには、今回のような実験を繰り返して可能な限り分析して経験を積むのが一番の早道だと思います。
固定のサイクル数を作る場合は、外部IO(メモリ)とかを読むと必ずパイプがストールするのでこの時間を元に計算するか、タイマ使うのが確実です。
高級言語やOSとは親和性が高いんですが、NOP 1個が○○nSecとかっていうのはできなくなって悲しいです。
それにしても、RAMに置いたプログラムは走らせられるんだろうか?
STのデータシートは図が少なくて見るのがつらい;;
by おる (2009-10-02 16:43)
> NOP 1個が○○nSecとかっていうのは
AVRですか(笑)、あれは便利。
> それにしても、RAMに置いたプログラムは走らせられるんだろうか?
メモリ領域別に何が出来るとかが決め事になっていて、勿論RAMからの実行も可能です。
by hamayan (2009-10-02 16:56)